

Following up on my previous post on Legacy Migration Strategies, I will be talking about the strangler pattern.
At its core, the approach is to take your original application, and replace it piece-by-piece by “strangling” it to death with each new component. The biggest reason for architecting with this approach in mind is to minimize the impact of the transition period to your new world. After all, the business can’t stop for a few months to years until a new system comes along to replace it. Likewise, the business also cannot be impacted too much as the app more than likely fulfills a critical function.
If this is the first time you’re hearing about it, I’m willing to bet your developers are well aware of it as this is the primary means of transitioning
the current code base towards microservices and the cloud.
The idea behind the pattern is that you “break up” your application into multiple services, and you route all communication to those services. Once the functionality has been replaced, then the legacy system can be switched off while users have no idea things changed, and the business continues to hum as if nothing happened.
How would this work? Normally a router would be introduced into the architecture. For web applications, this would be a reverse-proxy gateway. A webserver such as NGINX or HAProxy would be used in front of the application and route the appropriate traffic to the old legacy application and the new services where a change of hosts, and light configuration changes can be made to switch between the two systems. With a Web Application Firewall (WAF) or some other web gateway enforcing session management, it is important to have your reverse proxy in front of it to ensure that it knows as little about the underlying architecture as possible and different policies can be applied to the newer components if required. Even migrating to one of the various cloud providers, each provider has their own version of an API gateway that is used to enforce policies and provide proper load balancing.
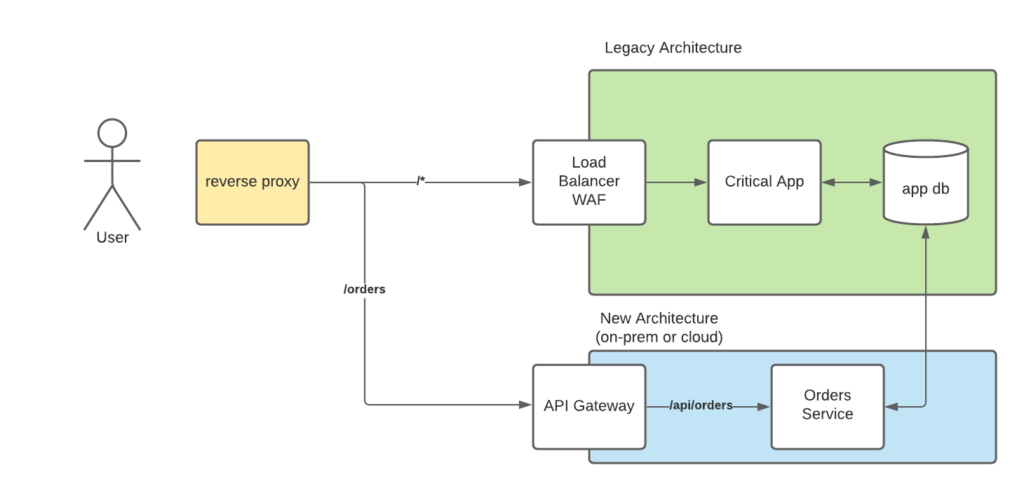
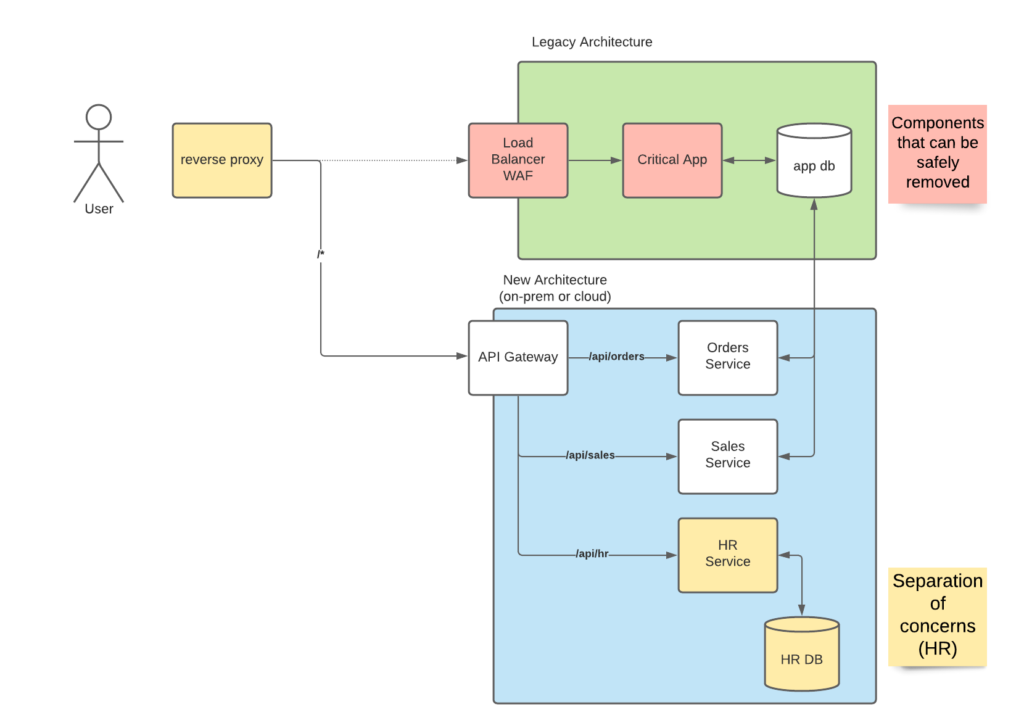
If your organization uses something along the lines of an enterprise service bus or message/event queue for sending asynchronous events, then this may require custom work to ensure proper replication and de-duplication of the messages. Just like the old system itself, this will be used until all data is flowing into the new system and can then be removed once the migration is complete. Luckily this is common enough to have it’s own technique called the anti-corruption pattern.
Lastly, I will caveat the use of strangler pattern with the one big assumption: the underlying data or request to the new service will not change. As with all modernization projects, one a domain is better understood, then new approaches will be developed to account for this understanding to make processing faster giving you quicker results, or easier to maintain costing a lot less time in your IT staff putting out fires late at night, or doing whatever it takes to keep the lights on.
The next article will cover the anti-corruption pattern, and how it can help
bridge the data translation gap.
If you would like to know more about how we can help you on your journey, then don’t hesitate to contact us!